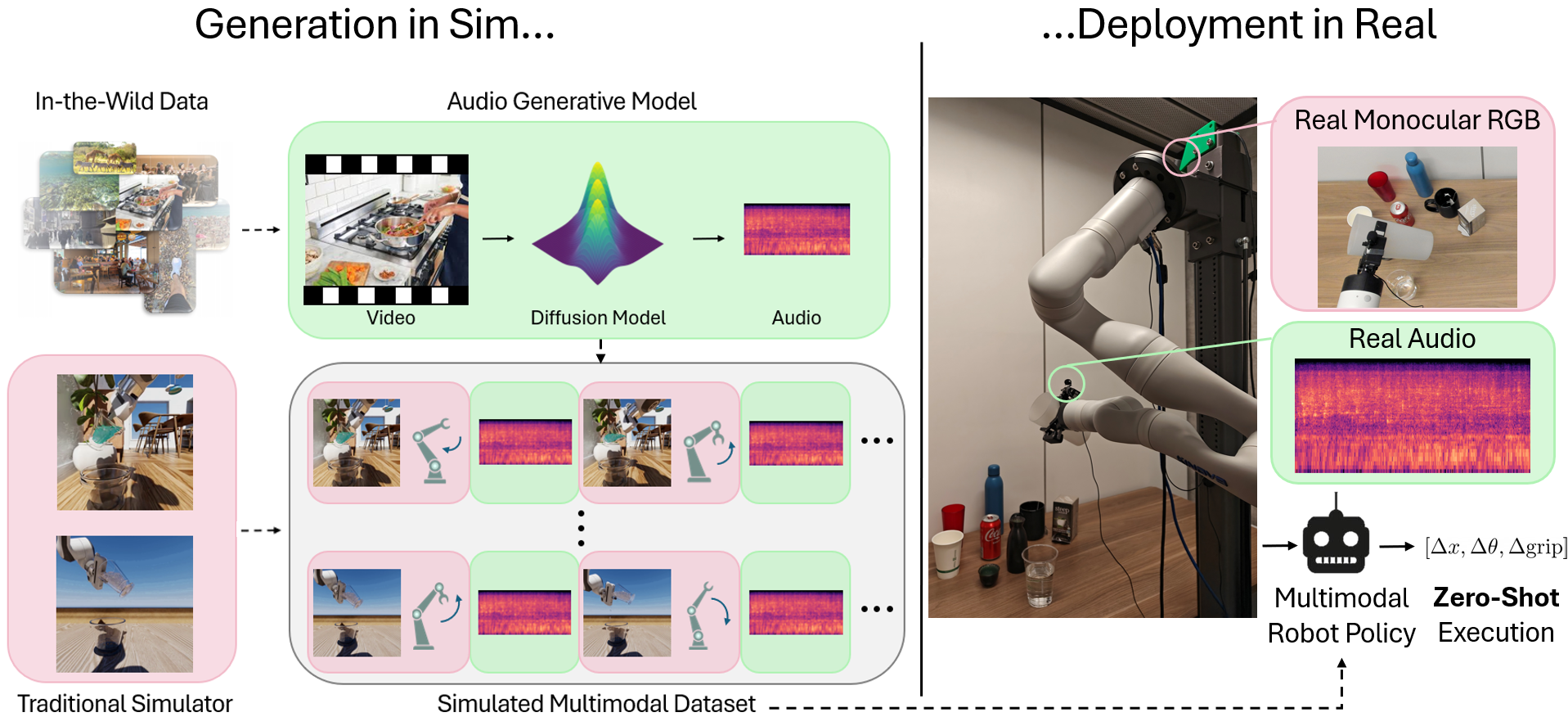
Robots must integrate multiple sensory modalities to act effectively in the real world. Yet, learning such multimodal policies at scale remains challenging. Simulation offers a viable solution, but while vision has benefited from high-fidelity simulators, other modalities (e.g. sound) remain difficult to simulate. As a result, sim-to-real transfer has succeeded primarily in vision-based tasks, with multimodal transfer largely unrealized. To address these challenges, we propose MULTIGEN: a framework that integrates large-scale generative models into traditional physics simulators, enabling multisensory simulation. We showcase our framework on the dynamic task of robot pouring, which inherently relies on multimodal feedback. By synthesizing realistic audio conditioned on simulation video, our method enables training on rich audiovisual trajectories—without any real robot data. We demonstrate effective zero-shot transfer to real-world pouring with novel containers and liquids, highlighting the potential of generative modeling to both simulate hard-to-model modalities and close the multimodal sim-to-real gap.
Our multimodal policies, trained only on simulated audiovisual and proprioceptive data, exhibit strong zero-shot generalization to a variety of real-world pouring tasks. This includes novel containers, novel liquids, and different environmental conditions.
Our multimodal policies demonstrate robustness to various environmental changes, such as different background noises and lighting conditions. This robustness stems from the rich sensory feedback provided by the audio modality, which helps the policy adapt to changes that may not be visually apparent.